

導入:なぜ標準のChatGPTはあなたの会社の「社内規定」を知らないのか?

ChatGPTの驚異的な文章生成能力を目の当たりにし、「これを自社の業務に活用できないか?」と考えるのは、もはや当然の時代になりました。あなたは、ChatGPTにこう質問したことがあるかもしれません。
「当社の最新の経費精算規定について教えて」
「先月のAプロジェクトの議事録を要約して」
「製品Bの技術マニュアルから、トラブルシューティングの方法をリストアップして」
しかし、返ってくる答えは決まって「申し訳ありませんが、私はあなたの会社の内部情報にアクセスできません」という、そっけないものです。ChatGPTは、インターネット上の膨大な公開情報で訓練された非常に賢いAIですが、その知識は2023年までの情報で止まっており、何よりもあなたの会社のクローズドな環境に存在する、生きた情報(社内規定、議事録、マニュアル、顧客データなど)を一切知らないのです。
この「社内情報への無知」こそが、多くの企業でChatGPTの本格的なビジネス活用を阻んでいる最大の壁です。この壁を突破し、ChatGPTを単なる「物知りの外部コンサルタント」から、自社のすべてを知り尽くした「頼れるエース社員」へと変貌させる魔法の技術、それが本記事のテーマである「RAG(ラグ)」です。
この記事では、非エンジニアの方でも理解できるように、RAGとは一体何なのか、どのような仕組みでChatGPTを賢くするのか、そして自社で導入するにはどうすればよいのかを、図解を交えながらゼロから徹底的に解説します。読み終える頃には、あなたの会社専用のChatGPTを構築するための、明確なロードマップが手に入っているはずです。
RAG(検索拡張生成)とは?ChatGPTを「自社専用AI」に変える技術

RAGという言葉は、ITに詳しくない方には聞き慣れないかもしれません。しかし、その概念は非常にシンプルで、私たちの日常的な行動に似ています。
RAGの基本概念:AIの“脳”に外部の知識を「検索させてから答える」仕組み
RAGとは、Retrieval-Augmented Generation(検索拡張生成)の略です。難しく聞こえますが、要するにこういうことです。
- Retrieval(検索): ユーザーから質問を受けたら、まず答えを生成する前に、関連する情報を探しに行く(検索する)。
- Augmented(拡張): 探し出した情報を、元の質問文に付け加える(拡張する)。
- Generation(生成): 拡張された、よりリッチな情報に基づいて、答えを生成する。
これは、私たちが仕事で質問に答えるプロセスと全く同じです。「昨日の会議の決定事項は?」と聞かれたら、私たちは自分の記憶(AIの事前学習知識)だけを頼りに答えるのではなく、まず手元の議事録(外部の知識ソース)を検索し、その内容を踏まえて、「昨日の会議では〇〇と決定しました」と答えますよね。
RAGは、この「カンニングペーパーを見てから答える」という、人間にとっては当たり前の能力を、ChatGPTに与える技術なのです。そして、その「カンニングペーパー」こそが、あなたの会社の社内文書やデータベースというわけです。
ChatGPTが抱える3つの企業導入課題(ハルシネーション・情報鮮度・専門性)
標準のChatGPTをそのまま企業で使おうとすると、RAGがないことによって、主に3つの深刻な課題に直面します。
- ハルシネーション(Hallucination):AIが、事実に基づかない、もっともらしい嘘の情報を生成してしまう現象です。事前学習した知識の中に答えがない場合、AIは「分かりません」と答える代わりに、それっぽい話を“創作”してしまうことがあります。これを顧客対応などで使ってしまうと、企業の信用を根本から揺るがしかねません。
- 情報の鮮度の欠如:ChatGPTの知識は、特定の時点(例:2023年初頭)でカットオフされています。そのため、それ以降に発表された新製品の情報や、昨日変更されたばかりの社内ルールについて尋ねても、答えることができません。
- 専門性・社内知識の欠如:前述の通り、インターネット上に公開されていない、あなたの会社独自の製品仕様、業務マニュアル、顧客とのやり取りの履歴、社内用語といった、専門的でクローズドな知識を一切持っていません。
RAGは、これらの課題をどう解決するのか?
RAGは、これら3つの課題に対する、極めてエレガントな解決策を提供します。
- ハルシネーションの抑制: RAGは、AIに「この検索結果(カンニングペーパー)に書かれていることだけを基に答えてください」と指示します。これにより、AIが自由に物語を創作する余地がなくなり、事実に基づいた、根拠のある回答を生成するようになります。
- 情報の最新化: RAGが参照する社内文書データベースを、常に最新の状態に保っておきさえすれば、AIはいつでも最新の情報を基に回答できます。昨日追加されたばかりの新製品マニュアルの内容にも、即座に対応可能です。
- 専門知識の付与: 社内に蓄積された膨大なマニュアル、過去の議事録、設計図書などをRAGの参照先にすることで、ChatGPTは一夜にして、あなたの会社で何十年も働いてきたベテラン社員のような知識を持つことができます。
このように、RAGはChatGPTの弱点をピンポイントで補い、信頼性が高く、最新かつ専門的な知識を持つ、ビジネスに特化したAIへと進化させるための鍵となる技術なのです。
【図解】RAGはどのように動くのか?技術的な仕組みを分かりやすく解説
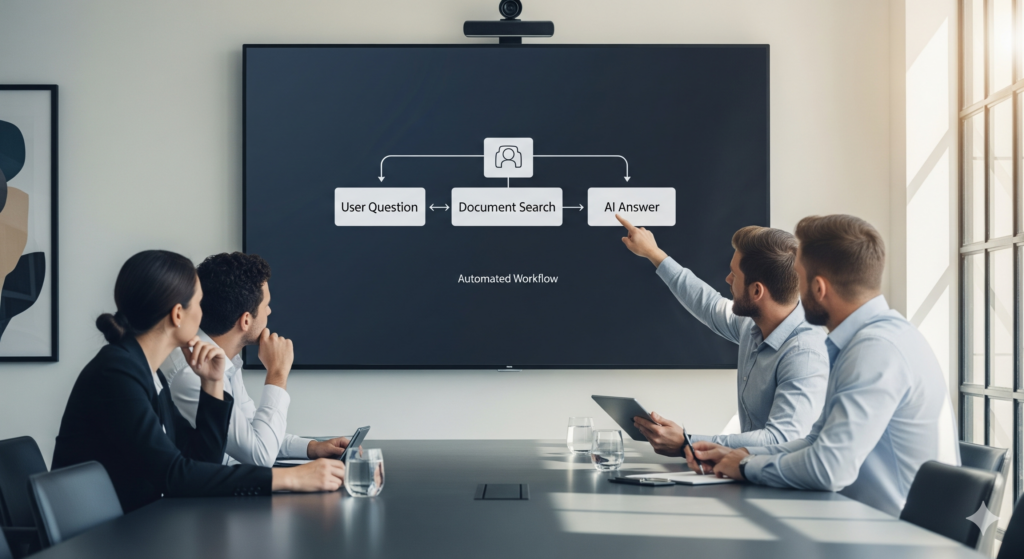
RAGの魔法のような能力は、どのような仕組みで実現されているのでしょうか。ここでは、その技術的な裏側を、2つのフェーズに分けて、非エンジニアの方にも分かるように図解します。
フェーズ1:知識の準備(Indexing)- 社内文書をAIが読める形に変換
AIが社内文書を検索できるようになるためには、まず「下準備」が必要です。本棚の膨大な本を、司書が整理して検索可能な目録を作る作業をイメージしてください。
- データソースの読み込み: まず、AIに参照させたい社内文書(PDF、Word、テキストファイル、Webページなど)をシステムに読み込ませます。
- チャンクへの分割: 長い文書をそのまま扱うのは難しいため、意味のある塊(段落ごとなど)で、小さなテキストの断片(チャンク)に分割します。
- ベクトル化(Embedding): これが最も重要なステップです。各チャンクを、Embeddingモデルという特殊なAIに通し、そのチャンクが持つ「意味」を、数値の羅列(ベクトル)に変換します。例えば、「犬」と「ワンちゃん」は、文字は違いますが意味が近いため、ベクトル空間上で非常に近い位置に配置されます。
- ベクトルデータベースへの格納: 生成された「チャンク」と、それに対応する「ベクトル」のペアを、ベクトルデータベースという特殊なデータベースに保存します。これで、AIが検索するための「目録」が完成です。この準備フェーズは、通常、文書を追加・更新するたびに実行されます。
フェーズ2:検索と生成(Retrieval & Generation)- ユーザーの質問に応答する流れ
準備が整ったら、いよいよユーザーが質問し、AIが回答するフェーズです。
- 質問のベクトル化: ユーザーが「経費精算の上限額は?」といった質問をすると、準備フェーズと同様に、この質問文もEmbeddingモデルによってベクトルに変換されます。
- 類似ベクトルの検索: システムは、質問のベクトルと「意味的に最も近い」ベクトルを、ベクトルデータベースから高速で検索します。これにより、「経費精算」や「上限額」という言葉だけでなく、「出張費」「接待交際費」「申請可能額」といった関連キーワードを含むチャンクも、候補として見つけ出すことができます。
- コンテキストの拡張: 検索で見つかった、関連性の高いチャンク(通常は複数)を、元の質問文と合体させ、ChatGPTのような大規模言語モデル(LLM)への拡張プロンプトを作成します。
(例:「以下の情報を参考に、次の質問に答えてください。情報:『出張旅費規程第5条:宿泊費の上限は1泊あたり12,000円とする…』『接待交際費規程第3条:一人あたりの上限は5,000円…』。質問:経費精算の上限額は?」)
- 回答の生成: LLMは、与えられた拡張プロンプト(検索結果というカンニングペーパー付きの質問)に基づいて、最終的な回答を生成します。「経費の種類によって異なりますが、例えば宿泊費の上限は1泊あたり12,000円です。」といった、具体的で根拠のある回答が生まれます。
RAGの心臓部「ベクトルデータベース」とは何か?
このRAGの仕組みを支える核心技術が「ベクトルデータベース」です。従来のデータベースが、「経費精算」というキーワードに完全に一致するテキストしか検索できなかったのに対し、ベクトルデータベースは言葉の「意味の近さ」で検索できるのが最大の特徴です。
これにより、ユーザーが多少曖昧な言葉で質問しても、あるいは社内用語を知らなくても、AIが文脈を理解し、適切な情報を見つけ出すことが可能になります。この「意味検索」能力こそが、RAGシステムの精度を大きく左右する、まさに心臓部と言えるのです。
RAGとファインチューニングは何が違う?目的別使い分けガイド

ChatGPTを自社向けにカスタマイズする方法として、RAGとしばしば比較されるのが「ファインチューニング」です。両者は目的も得意なことも全く異なるため、その違いを正しく理解し、適切に使い分けることが重要です。
ファインチューニングとは?AIの「性格や口調」を変えるアプローチ
ファインチューニングとは、既存の学習済みモデル(ChatGPTなど)に対して、特定のタスクに関する追加の学習データ(Q&Aペアなど)を与え、モデル自体の内部パラメータを微調整(チューニング)する手法です。
これは、例えるなら、博識な新入社員に、自社独自のコミュニケーションスタイルや専門用語の言い回しを、OJTで徹底的に教え込むようなものです。
得意なこと:
- 特定の文体やトーンの模倣: 「当社のカスタマーサポートのように、丁寧で共感的な口調で回答させる」
- 特定のフォーマットでの出力: 「必ずJSON形式で回答を出力させる」
- 専門用語の理解: 自社独自の業界用語や略語を正しく理解させる
苦手なこと:
- 新しい知識の追加: ファインチューニングは、AIの知識をアップデートするのではなく、あくまで既存の知識の「使い方」を調整するものです。昨日追加された新製品の情報を教え込むことはできません。
- ハルシネーションの抑制: 事実に基づかない情報を生成する傾向そのものを、根本的に抑制することは困難です。
RAGとファインチューニングのメリット・デメリット比較表
| 観点 | RAG(検索拡張生成) | ファインチューニング |
| 主目的 | 知識の注入・更新 | 振る舞い・スタイルの調整 |
| 得意なこと | 最新・社内情報に基づく回答、ハルシネーション抑制 | 特定の口調・文体、出力形式の模倣 |
| データの更新 | データベースの更新だけで容易 | モデルの再学習が必要で手間とコストがかかる |
| コスト | 比較的低コストで始められる | 高度な技術と計算資源が必要で高コスト |
| 根拠の提示 | 参照した文書を示せるため可能 | モデル内部の判断であり困難 |
| 導入の速さ | 比較的迅速に導入可能 | 準備と学習に時間がかかる |
| 一言でいうと | AIに「カンニング」させる | AIを「再教育」する |
いつRAGを使い、いつファインチューニングを検討すべきか
ほとんどの企業のユースケースにおいて、まず検討すべきはRAGです。
RAGを選ぶべきケース:
- 社内マニュアルやFAQに基づいた、正確な回答が求められる社内問い合わせ対応。
- 日々更新される製品情報や市場ニュースに基づいた回答が必要な営業支援。
- 回答の根拠を明確に示す必要があるコンプライアンス関連の業務。
事実(ファクト)に基づいた知識を提供したい場合は、ほぼすべてRAGが適しています。
ファインチューニングを検討すべきケース:
- RAGを導入した上で、さらにAIの回答スタイルを自社のブランドイメージに完全に合わせたい場合。
- 非常に特殊な業界用語が飛び交う、専門家同士の対話をシミュレートさせたい場合。
- 「〇〇という文章を、当社のプレスリリース風に書き換えて」といった、特定の文体への変換タスクが中心の場合。
結論として、まずはRAGで知識の土台を作り、必要であればファインチューニングで振る舞いを調整する、という組み合わせが最も強力なアプローチと言えるでしょう。
【ビジネス活用】ChatGPTとRAGを組み合わせた5つの導入事例

RAGによって自社の知識を手に入れたChatGPTは、具体的にどのようなビジネスシーンで活躍するのでしょうか。ここでは、多くの企業で既に成果を上げている、代表的な5つの活用事例を紹介します。これらは、あなたの会社でRAG導入を検討する際の、具体的な出発点となるはずです。
事例①:社内問い合わせ対応チャットボット(総務・人事・情シス)
【課題】
総務、人事、情報システムといったバックオフィス部門には、「経費精算の締め日はいつですか?」「PCのパスワードを忘れました」「育児休暇の申請手続きを教えてください」といった、同じような質問が毎日繰り返し寄せられます。これらの対応に、担当者の貴重な時間が奪われ、本来注力すべき戦略的な業務が後回しになっていました。
【RAGによる解決策】
就業規則、経費精算マニュアル、ITサポートFAQ、福利厚生ガイドといった、社内のあらゆる規程・マニュアル類をRAGの知識ソースとして読み込ませた、24時間365日対応の社内チャットボットを構築します。
【導入効果】
- 従業員の自己解決促進: 従業員は、担当者を探して電話やメールをする手間なく、チャットで質問するだけで、いつでも即座に正確な回答を得られます。
- バックオフィス部門の工数削減: 定型的な問い合わせ対応業務が最大で80%以上削減され、担当者は制度設計やセキュリティ強化といった、より専門性の高い業務に集中できるようになります。
- ナレッジの一元化: 散在しがちな社内ナレッジがRAGシステムに集約され、情報の属人化を防ぎ、組織全体の知識レベルが向上します。
事例②:営業向け製品知識・提案ナレッジ検索システム
【課題】
営業担当者は、多岐にわたる自社製品の仕様、価格、導入事例、競合製品との比較情報などを、常に最新の状態で把握しておく必要があります。しかし、情報が社内の様々な場所に散在しているため、提案書作成のたびに資料探しに多大な時間を費やしていました。
【RAGによる解決策】
製品カタログ、技術仕様書、価格表、過去の成功提案書、競合分析レポート、顧客からの導入事例インタビューなどを知識ソースとし、営業担当者専用の「AIブレイン」を構築します。
【導入効果】
- 提案準備時間の劇的な短縮: 「〇〇業界の顧客に、製品Aと競合のB製品を比較した上で提案したい。参考になる過去の提案書と導入事例を3つ教えて」といった複雑な質問にも、AIが瞬時に最適な情報を提供。提案書の作成時間が大幅に短縮されます。
- 提案の質の向上: トップセールスの優れた提案書や、最新の成功事例に誰もが簡単にアクセスできるようになり、営業組織全体の提案の質が標準化され、受注率の向上に繋がります。
- 新人営業の即戦力化: OJTだけでは習得に時間がかかる膨大な知識を、AIがサポート。新人でもベテランのような知識武装で顧客対応に臨めるようになり、育成期間が短縮されます。
事例③:技術文書・マニュアル検索システム(開発・製造・保守)
【課題】
開発部門や製造現場では、過去の設計図書、膨大な技術仕様書、複雑な運用マニュアルの中から、必要な情報を探し出すのが困難でした。特に、退職したベテランが残した文書などは、作成者でなければ意図を汲み取れない「暗黙知」の塊となっていました。
【RAGによる解決策】
過去数十年分の設計文書、技術規格書、保守点検マニュアル、トラブルシューティング報告書などをRAGに読み込ませ、技術的な暗黙知を形式知化するナレッジシステムを構築します。
【導入効果】
- 問題解決の迅速化: 「製品Cでエラーコード503が発生した場合の、過去の対応事例と解決策を教えて」といった質問に対し、AIが関連する報告書を横断的に検索し、最も可能性の高い原因と対処法を提示。ダウンタイムの短縮に貢献します。
- 技術伝承の促進: 退職した技術者のノウハウが、AIを通じて次世代に引き継がれます。若手技術者が、過去の膨大な資産を容易に活用できるようになります。
- 品質向上: 過去の設計ミスや不具合報告をAIが分析し、「新しい設計を行う上で、過去の〇〇の失敗から学ぶべき点は?」といった問いに答えることで、再発防止と製品品質の向上に繋がります。
事例④:顧客サポートの効率化とオペレーター支援
【課題】
コールセンターやカスタマーサポート部門では、オペレーターのスキルレベルによって顧客対応の質にばらつきが生じていました。また、新人オペレーターが複雑な問い合わせを受けた際、回答を見つけるまでに顧客を待たせてしまうことが課題でした。
【RAGによる解決策】
製品マニュアル、FAQ、過去の問い合わせ履歴、対応スクリプトなどを知識ソースとし、オペレーターをリアルタイムで支援するAIアシスタントを構築します。
【導入効果】
- 一次回答時間の短縮: 顧客からの問い合わせ内容をAIがリアルタイムで分析し、オペレーターの画面に回答候補や参照すべきマニュアルの該当箇所を提示。顧客の待ち時間を大幅に短縮し、顧客満足度を向上させます。
- 対応品質の均一化: すべてのオペレーターが、AIによって標準化された最適な回答案を基に対応できるようになり、対応品質のばらつきが解消されます。
- オペレーターの負担軽減: 複雑な問い合わせに対する精神的な負担が軽減され、オペレーターのストレス軽減と離職率の低下に繋がります。
事例⑤:研究開発における論文・特許情報の高度な分析
【課題】
研究開発部門では、新しい技術を開発するために、世界中の何千、何万という学術論文や特許公報を読み解く必要がありますが、そのリサーチには膨大な時間がかかっていました。
【RAGによる解決策】
特定の技術分野に関する学術論文や特許データベースをRAGの知識ソースとし、研究者専用の高度なリサーチアシスタントを構築します。
【導入効果】
- リサーチの超効率化: 「〇〇という技術に関する、過去5年間の主要な論文を10本挙げ、それぞれの貢献と限界点を要約して」といった高度な指示に対し、AIが瞬時にサマリーを提供。研究者は、文献を読む時間を節約し、実験や考察といった創造的な活動に集中できます。
- 新たな着想の発見: 「技術Aと技術Bを組み合わせた研究は存在する?もしなければ、どのような可能性があるか?」といった問いに対し、AIが膨大な文献を横断的に分析し、人間では気づきにくい、新たな研究の切り口やイノベーションのヒントを発見する手助けをします。
ChatGPTでRAGを実装する方法:3つの選択肢とメリット・デメリット

自社でRAGシステムを導入したいと考えたとき、その実現方法には大きく分けて3つの選択肢があります。それぞれにメリットとデメリットがあり、自社の技術力、予算、そして目的に合わせて最適な方法を選ぶことが重要です。
選択肢①:自社でフルスクラッチ開発する場合(LangChain等のライブラリ活用)
【概要】
Pythonなどのプログラミング言語と、LangChainやLlamaIndexといったオープンソースのライブラリ(開発を助ける部品セット)を使い、RAGの仕組みをゼロから自社で構築する方法です。
【メリット】
- 最高の柔軟性とカスタマイズ性: 自社の要件に合わせて、検索アルゴリズムやデータの前処理方法など、システムのあらゆる部分を自由に設計・変更できます。
- ベンダーロックインの回避: 特定の企業のサービスに依存しないため、将来的に利用するLLMやデータベースを自由に変更できます。
- 社内技術力の向上: 開発プロセスを通じて、AIに関する高度な技術力が社内に蓄積されます。
【デメリット】
- 高度な技術スキルが必須: AI、機械学習、クラウドインフラに関する専門知識を持つエンジニアチームが不可欠です。
- 高い開発コストと時間: 設計から開発、テスト、運用まで、多くの時間と人件費がかかります。
- 継続的なメンテナンス負担: システムの運用・保守・アップデートをすべて自社で行う必要があります。
【向いている企業】
AI専門のエンジニアチームを社内に擁し、RAGを自社のコア技術として戦略的に活用したい、技術力の高い大企業やIT企業。
選択肢②:クラウドプラットフォームのサービスを利用する場合(Azure, AWS, GCP)
【概要】
Microsoft Azure、Amazon Web Services (AWS)、Google Cloud Platform (GCP)といった大手クラウドベンダーが提供する、RAG構築のためのマネージドサービス(管理・運用を代行してくれるサービス)を組み合わせて利用する方法です。
例: Azure AI Search + Azure OpenAI Service / Amazon Bedrock / Google Vertex AI Search
【メリット】
- 開発負荷の軽減: サーバーの管理や、基本的な検索エンジンの構築といった、インフラ部分をクラウドベンダーに任せられるため、開発の手間を大幅に削減できます。
- スケーラビリティ: 利用するデータ量やユーザー数の増減に合わせて、柔軟にシステム規模を拡大・縮小できます。
- エコシステムとの連携: 各社が提供する他のクラウドサービス(データベース、セキュリティ機能など)とスムーズに連携できます。
【デメリット】
- 一定の技術スキルは必要: フルスクラッチ開発ほどではないものの、各クラウドサービスの仕様を理解し、適切に設定・組み合わせるための専門知識が必要です。
- プラットフォームへの依存: 特定のクラウドベンダーの技術に依存することになります(ベンダーロックイン)。
- 利用量に応じた課金: ランニングコストが、データの検索回数や処理量に応じて変動するため、コスト管理が複雑になる場合があります。
【向いている企業】
クラウドインフラの利用経験があるエンジニアが社内にいて、開発の自由度と管理の手間のバランスを取りたい、中堅〜大企業。
選択肢③:法人向けRAG構築・チャットボットサービスを利用する場合
【概要】
RAGシステムの構築から運用までを、専門のSaaS(Software as a Service)企業が提供するパッケージサービスとして利用する方法です。多くのサービスでは、プログラミング不要で、文書ファイルをアップロードするだけで社内AIチャットボットを構築できます。
【メリット】
- 専門知識が不要で、導入が最も迅速: 非エンジニアでも、数時間〜数日でRAGシステムを導入できます。
- 低コストでスモールスタート可能: 月額数万円から利用できるサービスも多く、初期投資を抑えてPoC(概念実証)を始めたい場合に最適です。
運用・保守の手間がゼロ: システムのアップデートやセキュリティ対策は、すべてサービス提供会社が行ってくれます。
【デメリット】
- カスタマイズ性の低さ: サービス側で用意された機能の範囲内でしか利用できず、独自の細かいカスタマイズは難しい場合があります。
- サービスへのデータ依存: 自社の重要なナレッジを、外部のSaaS企業に預けることになります。
- 拡張性の限界: 非常に大規模な利用や、複雑なシステム連携には対応できない場合があります。
【向いている企業】
AI専門のエンジニアが社内におらず、まずは迅速かつ低コストでRAGの効果を試してみたい、すべての中小企業〜大企業の部門単位での導入。
企業の規模と目的に合わせた最適な実装方法の選び方
| 観点 | ① フルスクラッチ開発 | ② クラウドサービス利用 | ③ SaaSサービス利用 |
| 技術力 | 非常に高い | 中程度 | 不要 |
| コスト | 高い | 中程度 | 低い |
| 導入スピード | 遅い | 中程度 | 速い |
| 柔軟性 | 高い | 中程度 | 低い |
| おすすめ | 技術系大企業 | 中堅〜大企業 | すべての企業(特にPoC) |
結論として、ほとんどの企業にとって、最初のステップは「③SaaSサービス利用」で迅速にPoCを行い、その効果と課題を実感することです。 その上で、より高度なカスタマイズが必要になった場合に、「②クラウドサービス利用」や「①フルスクラッチ開発」へとステップアップしていくのが、最もリスクの低い賢明な進め方と言えるでしょう。
RAGシステムの精度を左右する5つの重要ポイント

RAGシステムは、導入すれば必ずしも高い精度の回答を出してくれるわけではありません。その性能は、いくつかの重要な要素によって大きく左右されます。「ゴミを入れれば、ゴミが出てくる(Garbage In, Garbage Out)」という原則は、RAGの世界でも同様です。ここでは、RAGシステムの回答精度を高め、本当に「使える」AIにするための5つの重要なチューニングポイントを解説します。
ポイント①:データ品質(参照させる情報の正確性と網羅性)
【重要性】 RAGシステムの知識の源泉であり、精度に最も直接的な影響を与える要素です。
【解説】
AIは、与えられた情報源(データソース)の内容を絶対的な「正解」として扱います。そのため、参照させる社内文書の内容が古かったり、間違っていたり、あるいは情報が不足していたりすると、AIも必然的に古く、間違った、不完全な回答を生成してしまいます。
【実践のヒント】
- データの棚卸しとクレンジング: RAGを導入する前に、AIに読み込ませる文書を棚卸しし、内容が古くなっているマニュアルや、重複している情報を整理・削除(クレンジング)するプロセスが不可欠です。
- 信頼できる情報源の選定: まずは、社内規程や公式マニュアルといった、内容の正確性が担保された「信頼できる情報源」からスモールスタートします。
- 網羅性の確保: 例えば、社内問い合わせ対応ボットを作るなら、関連する規程だけでなく、過去のFAQや問い合わせ履歴もデータソースに加えることで、より多様な質問に答えられるようになります。
ポイント②:データの前処理(チャンク分割の最適化)
【重要性】 情報をAIが理解しやすい「意味のある塊」に、どう分割するかという、職人技的な要素です。
【解説】
RAGでは、文書を小さな「チャンク」に分割してからベクトル化しますが、この分割(チャンキング)の仕方が検索精度に大きく影響します。
- チャンクが小さすぎる場合: 文脈が失われ、断片的な情報しか検索できなくなります。
- チャンクが大きすぎる場合: 関係のない情報が多く含まれるため、ノイズが多くなり、回答の精度が低下します。
【実践のヒント】
- 意味的な区切りを意識する: 単純に文字数で区切るのではなく、段落やセクション、箇条書きといった、文章の「意味的な区切り」でチャンクを作成するのが基本です。
- チャンクのオーバーラップ: チャンク同士の文脈が途切れないように、チャンクの終わりと次のチャンクの始まりを、数十文字程度重ねる(オーバーラップさせる)手法が有効です。
- 試行錯誤と調整: 最適なチャンクサイズは、文書の種類や内容によって異なります。いくつかのパターンを試し、どちらがより精度の高い回答を生成できるかを比較・調整するプロセスが重要です。
ポイント③:検索アルゴリズムの選定
【重要性】 ユーザーの質問に対して、膨大な知識の中から最も関連性の高い情報を、いかに賢く見つけ出すかという検索能力です。
【解説】
RAGの検索フェーズは、単純な類似ベクトル検索だけではありません。より高度な検索手法を組み合わせることで、精度を向上させることができます。
【実践のヒント】
- ハイブリッド検索: ベクトルによる「意味検索」と、従来のキーワード検索を組み合わせる手法です。製品型番や特定の固有名詞など、キーワードが重要な質問に対して特に有効です。
- 再ランキング(Re-ranking): 検索で得られた上位数十件の候補を、より高性能な別のAIモデルを使って再度スコアリングし、関連性の順位を並べ替える(再ランキングする)手法です。検索の最終的な精度を高めることができます。
ポイント④:プロンプトエンジニアリング
【重要性】 検索で見つけた情報を、最終的にどのようにChatGPT(LLM)に渡し、どのように回答を生成させるかを指示する「魔法の呪文」です。
【解説】
RAGシステムにおけるプロンプトは、単にユーザーの質問をLLMに渡すだけではありません。検索結果をどう活用すべきかを、LLMに対して明確に指示する必要があります。
【実践のヒント】
- 役割と制約の明確化: プロンプトに「あなたは当社の優秀なサポート担当です。以下の検索結果のみを基にして、ユーザーの質問に日本語で回答してください。検索結果に答えがない場合は、『分かりません』と答えてください」といった、役割と厳格な制約条件を与えることが、ハルシネーション抑制に極めて効果的です。
- 出力形式の指定: 回答を箇条書きにする、表形式にする、参照した文書名を必ず記載するなど、出力形式を細かく指定することで、ユーザーにとってより分かりやすく、信頼性の高い回答を生成させることができます。
ポイント⑤:継続的な評価とチューニング
【重要性】 RAGシステムは、一度作ったら終わりの「完成品」ではなく、育て続ける「生き物」です。
【解説】
ユーザーが実際にシステムを使い始めると、想定していなかった質問や、うまく答えられなかったケースが必ず出てきます。これらのフィードバックこそが、システムをより賢くするための最も貴重なデータです。
【実践のヒント】
- フィードバック機能の実装: AIの回答に対して、ユーザーが「役に立った」「役に立たなかった」といった評価を付けられる簡単なフィードバック機能を実装します。
- ログの定期的レビュー: 「役に立たなかった」と評価された質問や、AIが「分かりません」と答えた質問のログを定期的に(例:月次で)レビューします。
- 継続的な改善サイクル: レビューの結果、「データソースに情報が不足していた」「チャンクの分割方法が悪かった」「プロンプトの指示が曖昧だった」といった原因を特定し、データソースの追加やシステムのチューニングを行います。このPDCAサイクルを回し続けることが、RAGシステムの価値を長期的に高めていきます。
RAG導入の課題と注意点:導入前に知っておくべき現実

RAGは非常に強力な技術ですが、導入すればすべての問題が解決する銀の弾丸ではありません。その導入と運用には、いくつかの現実的な課題や注意点が伴います。これらを事前に理解し、対策を講じておくことが、プロジェクトを成功に導くために不可欠です。
課題①:実装の技術的な複雑さとコスト
【課題の詳細】
本稿で解説した通り、高性能なRAGシステムを自社で構築(フルスクラッチ開発やクラウドサービス利用)しようとすると、ベクトルデータベース、Embeddingモデル、LLMなど、様々なコンポーネントに関する専門知識が必要となり、技術的なハードルは決して低くありません。また、これらの専門人材の確保や、クラウドサービスの利用料など、相応のコストが発生します。
【対策と注意点】
- スモールスタートの徹底: 最初から完璧な大規模システムを目指すのではなく、まずは「SaaSサービスを利用」し、特定の部門や用途に絞ってPoC(概念実証)から始めることを強く推奨します。これにより、最小限のコストとリスクでRAGの価値を実証できます。
- TCO(総保有コスト)の意識: ライセンス費用だけでなく、開発にかかる人件費、運用・保守コスト、そして従業員の教育コストまで含めた総保有コスト(TCO)を算出し、投資対効果を判断することが重要です。
課題②:応答速度(パフォーマンス)の低下
【課題の詳細】
RAGは、ユーザーからの質問のたびに「検索」というプロセスを挟むため、標準のChatGPTに比べて回答が生成されるまでの時間(レイテンシー)が長くなる傾向があります。応答があまりに遅いと、ユーザー体験を損ない、使われないシステムになってしまう可能性があります。
【対策と注意点】
- 適切なインフラ選定: 検索対象となるデータ量や、想定される同時アクセスユーザー数に応じて、十分な性能を持つベクトルデータベースやコンピューティングリソースを選定する必要があります。
- パフォーマンス・チューニング: 検索アルゴリズムの最適化や、キャッシュ(一度検索した結果を一時的に保存しておく仕組み)の活用など、応答速度を向上させるための技術的なチューニングが必要になる場合があります。SaaSサービスを選ぶ際には、無料トライアルなどを活用し、応答速度が実用レベルにあるかを確認することが重要です。
課題③:高度なセキュリティ対策の必要性
【課題の詳細】
RAGは、企業の最も重要な資産である「社内データ」を取り扱います。そのため、そのデータの管理には、標準のChatGPTを利用する際よりも、さらに高度で厳格なセキュリティ対策が求められます。
【対策と注意点】
- アクセス権管理の徹底: RAGシステムは、ユーザーが本来持つべきアクセス権限を厳密に反映する仕組みでなければなりません。あるユーザーが、自分がアクセス権を持たないはずの他部門の機密情報に、RAGを通じてアクセスできてしまうようなことがあっては絶対になりません。
- データガバナンスの確立: 誰が、どのデータをRAGの知識ソースとして登録できるのか、その承認プロセスはどうするのか、といったデータガバナンスに関する明確なルールを定める必要があります。
- 信頼できるベンダーの選定: SaaSサービスやクラウドプラットフォームを利用する場合は、SOC 2などの第三者認証を取得しているか、データ暗号化やアクセスログの管理といったセキュリティ機能が充実しているかなど、ベンダーのセキュリティ体制を厳しく評価する必要があります。
課題④:「検索失敗」による不正確な回答のリスク
【課題の詳細】
RAGはハルシネーションを抑制するのに効果的ですが、万能ではありません。もし、検索フェーズでユーザーの質問と関連性の低い、間違った情報を検索してきてしまった場合、LLMはその間違った情報を基に、もっともらしいが不正確な回答を生成してしまいます。これは「検索の失敗」に起因する、新たな種類のハル-シネーションと言えます。
【対策と注意点】
- 根拠の明示: RAGシステムは、AIが回答を生成する際に参照した情報源(文書名やページ番号など)を、回答と併せてユーザーに提示する機能を必ず実装すべきです。これにより、ユーザーは回答の正しさを自分自身で検証(ファクトチェック)することができます。
- 継続的な評価とチューニング: 前述の通り、ユーザーからのフィードバックやログ分析を通じて、なぜ検索に失敗したのかを継続的に分析し、システムの精度を改善していくプロセスが不可欠です。
よくある質問(FAQ):RAGとChatGPTに関する疑問を解消

RAGとChatGPTの組み合わせについて、導入を検討する担当者が抱きがちな、より突っ込んだ質問にQ&A形式でお答えします。
RAGを導入すれば、ハルシネーションは完全になくなりますか?
A: いいえ、完全にはなくなりません。しかし、大幅に抑制することができます。 RAGは、AIが参照すべき「根拠」を与えることで、事実に基づかない情報を創作するハルシネーションを劇的に減らします。しかし、前述の通り「検索の失敗」によって間違った根拠を提示してしまったり、あるいは検索した複数の情報源の内容が矛盾していたりする場合、AIが混乱して不正確な回答を生成する可能性は残ります。そのため、「AIの回答は、必ず根拠を確認し、最終的には人間が責任を持つ」という原則は、RAGを導入しても変わりません。
日本語の社内文書でも、RAGはうまく機能しますか?
A: はい、非常にうまく機能します。 近年のEmbeddingモデルやLLMは、日本語の処理能力が飛躍的に向上しています。日本語特有の文法や言い回しのニュアンスを高い精度で理解し、ベクトル化することが可能です。ただし、文書内で使われる専門用語や社内用語が多い場合は、それらを適切に処理するためのチューニングが必要になることもあります。多くの法人向けSaaSサービスは、日本語環境での利用を前提に最適化されています。
RAGとChatGPTの組み合わせに、最適なLLMはありますか?
A: 一概に「これが最適」というものはありませんが、考慮すべき点はあります。
- OpenAIのモデル(GPT-4, GPT-3.5 Turboなど): ChatGPTとの親和性が最も高く、一般的な文章生成能力や対話能力に優れています。多くのRAGシステムの標準的な選択肢です。
- AnthropicのClaude: より長い文脈の理解に長けているとされ、長大な文書を扱うRAGに適している場合があります。また、倫理的な制約が強く、安全性を重視する場合に選ばれることがあります。
- オープンソースのモデル(Llama, Mistralなど): 自社でモデルを運用・管理できるため、高度なカスタマイズやセキュリティを求める場合に選択肢となりますが、運用には専門知識が必要です。
結論としては、まずは標準的なGPT-4などで試し、自社の用途やコスト、求める応答速度などに応じて、他のモデルを比較検討していくのが良いでしょう。
まとめ

本記事では、ChatGPTを自社専用の賢いAIへと進化させる技術「RAG」について、その基本概念から、技術的な仕組み、具体的なビジネス活用事例、そして導入・運用における実践的なポイントまでを、網羅的に解説してきました。
標準のChatGPTが、インターネットの知識を持つ「博識な外部コンサルタント」だとすれば、RAGを導入したChatGPTは、あなたの会社の歴史と文脈をすべて理解し、常に最新の情報で武装した「頼れるエース社員」に生まれ変わります。
ハルシネーションのリスクを抑制し、社内の専門知識をAIに与え、日々更新される情報をリアルタイムに反映させる。RAGは、これまで多くの企業が感じていたChatGPT導入への不安を解消し、その活用を「実験」のフェーズから、日々の業務に不可欠な「実用」のフェーズへと引き上げる、まさに鍵となる技術です。
社内問い合わせ対応の自動化、営業ナレッジの共有、技術伝承の促進――。RAGが拓く可能性は、単なる業務効率化に留まりません。それは、組織に埋もれた暗黙知を掘り起こし、従業員一人ひとりの能力を拡張し、企業全体の競争力を向上させる、DXの本質的な推進力となります。
もちろん、その導入には適切な計画と、本記事で解説したような様々な課題への配慮が必要です。しかし、まずはSaaSサービスなどを活用して、小さく、そして迅速にその効果を試してみること。その一歩が、あなたの会社の働き方を根本から変え、AIとの協業が当たり前となる新しい未来への扉を開くことになるでしょう。